Caching Strategies for High-Traffic APIs
The Cost of Every Database Query
At scale, every unnecessary database query is money wasted. A well-placed cache can:
- Reduce latency from 200ms to 5ms
- Cut database load by 95%
- Save thousands in cloud costs
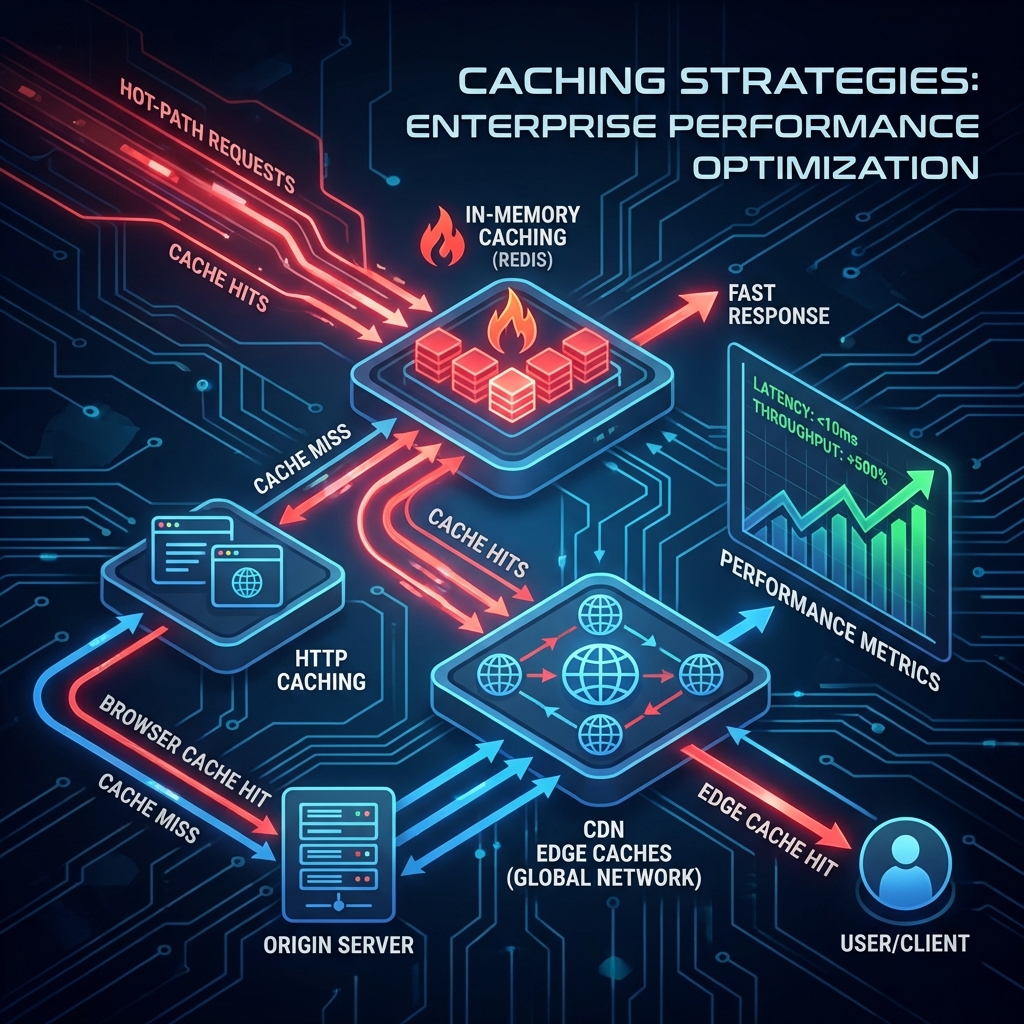
The Cache Hierarchy
Layer 1: HTTP Caching (Browser + CDN)
Free performance for static or rarely-changing data.
@GetMapping("/api/products/{id}")
public ResponseEntity<Product> getProduct(@PathVariable String id) {
Product product = productService.find(id);
return ResponseEntity.ok()
.cacheControl(CacheControl.maxAge(1, TimeUnit.HOURS).cachePublic())
.eTag(product.getVersion())
.body(product);
}
This response is cached by:
- User’s browser
- CDN (Cloudflare, Fastly)
- Intermediate proxies
Result: 99% of requests never hit your server.
Layer 2: Application Cache (Spring Cache + Redis)
For dynamic data that’s expensive to compute.
@Cacheable(value = "users", key = "#id")
public User getUser(String id) {
return database.findUser(id); // Only called on cache miss
}
@CacheEvict(value = "users", key = "#user.id")
public void updateUser(User user) {
database.save(user); // Invalidates cache
}
Cache Eviction Policies
| Policy | When to Use |
|---|---|
| TTL (Time-To-Live) | Data has natural expiration (session tokens) |
| LRU (Least Recently Used) | Limited cache size, favor hot data |
| Event-Based Eviction | Data changes are known (user updates profile) |
Redis TTL Example
@Bean
RedisCacheConfiguration cacheConfiguration() {
return RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofHours(1))
.disableCachingNullValues();
}
Cache-Aside vs. Read-Through
Cache-Aside (Manual)
public User getUser(String id) {
User cached = cache.get(id);
if (cached != null) return cached;
User user = database.find(id);
cache.put(id, user);
return user;
}
Read-Through (Spring Abstraction)
@Cacheable("users")
public User getUser(String id) {
return database.find(id); // Cache handled automatically
}
Recommendation: Use Spring’s @Cacheable unless you need fine-grained control.
The Thundering Herd Problem
When a popular cache key expires, all requests hit the database simultaneously.
Solution: Cache Stampede Prevention
@Cacheable(value = "products", sync = true) // Only one thread fetches
public Product getProduct(String id) {
return database.find(id);
}
The sync flag ensures only one thread computes the value while others wait.
Multi-Level Caching
Combine local + distributed caches for best performance:
@Configuration
public class CacheConfig {
@Bean
public CaffeineCacheManager localCache() {
var manager = new CaffeineCacheManager();
manager.setCaffeine(Caffeine.newBuilder()
.expireAfterWrite(5, TimeUnit.MINUTES)
.maximumSize(10_000)
);
return manager;
}
@Bean
public RedisCacheManager distributedCache(RedisConnectionFactory factory) {
return RedisCacheManager.builder(factory)
.cacheDefaults(RedisCacheConfiguration.defaultCacheConfig())
.build();
}
}
Flow: Check local cache → Check Redis → Hit database
Cache Invalidation: The Hard Problem
“There are only two hard things in Computer Science: cache invalidation and naming things.” — Phil Karlton
Pattern 1: Write-Through
Update cache and database together:
@CachePut(value = "users", key = "#user.id")
public User updateUser(User user) {
return database.save(user);
}
Pattern 2: Event-Driven Invalidation
@EventListener
public void onUserUpdated(UserUpdatedEvent event) {
cacheManager.getCache("users").evict(event.getUserId());
}
Performance Impact
| Scenario | No Cache | With Redis Cache | Improvement |
|---|---|---|---|
| Product Lookup | 180ms | 8ms | 22x faster |
| Database Load | 100% | 5% | 95% reduction |
| Cost (AWS RDS) | $500/month | $50/month + $30 (Redis) | 84% savings |
Conclusion
Caching is the highest-ROI performance optimization. Start with HTTP caching for static data, add Redis for dynamic data, and use local caches for ultra-low latency. Just remember: cache invalidation is hard—design for it from day one.
Building high-performance systems? Check out Reactive Streams or Java 21 Tricks.